기계 번역
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
기계 번역은 언어를 자동적으로 번역하는 기술로, 초기에는 문법 규칙을 기반으로 하는 규칙 기반 기계 번역(RBMT)이 사용되었으나, 1988년 IBM이 통계 기반 기계 번역(SMT) 기술을 도입하면서 혁신적인 변화를 겪었다. 이후 빅데이터를 활용한 통계적 기법이 발전하면서 구문 구조를 이용한 번역 방법, 신경망 기계 번역(NMT) 등이 등장했다. 기계 번역은 다양한 접근 방식을 통해 발전해 왔으며, 현재는 대규모 언어 모델(LLM)을 활용한 챗GPT와 같은 서비스도 등장했다. 기계 번역은 일반 사용자들이 모바일 기기, 소셜 네트워킹, 위키백과 문서 번역 등 다양한 분야에서 활용되고 있으며, 전문 번역에서는 번역 지원 도구로 사용된다. 하지만 중의성 해소, 비표준어 처리, 개체명 인식 등의 문제와 한국어의 특수성, 그리고 번역의 정확성 및 뉘앙스 이해의 한계가 존재하며, 의료 및 법률 분야에서는 신중한 사용이 요구된다. 기계 번역 시스템의 평가는 수동 및 자동 평가를 통해 이루어지며, 저작권 문제와 관련하여서는 번역 결과의 창작성 여부가 중요한 요소로 작용한다.
더 읽어볼만한 페이지
- 기계 번역 - 시스트란
시스트란은 1960년대 초 기계 번역 시스템으로 시작하여 50개 이상의 언어를 지원하며, 현재 한국의 CSLi에 인수되었다. - 기계 번역 - 신경망 기계 번역
신경망 기계 번역은 딥 러닝 기술로 문장을 번역하며, 통계적 기계 번역보다 메모리 효율이 높고 모델 전체가 함께 훈련되어 성능을 극대화하는 특징을 가지며, 최근에는 트랜스포머 기반 대규모 언어 모델을 활용하는 연구가 활발하다. - 전산언어학 - 알고리즘
알고리즘은 문제 해결을 위한 명확하고 순서화된 유한 개의 규칙 집합으로, 알콰리즈미의 이름에서 유래되었으며, 수학 문제 해결 절차로 사용되다가 컴퓨터 과학에서 중요한 역할을 하며 다양한 방식으로 표현되고 효율성 분석을 통해 평가된다. - 전산언어학 - 단어 의미 중의성 해소
단어 의미 중의성 해소(WSD)는 문맥 내 단어의 의미를 파악하는 계산 언어학 과제로, 다양한 접근 방식과 외부 지식 소스를 활용하여 연구되고 있으며, 다국어 및 교차 언어 WSD 등으로 발전하며 국제 경연 대회를 통해 평가된다. - 인공지능의 응용 - 가상 비서
가상 비서는 음성 또는 텍스트 입력을 해석하여 정보 제공, 일정 관리, 기기 제어 등 다양한 작업을 수행하는 소프트웨어 에이전트로서, 시리, 알렉사, 구글 어시스턴트와 같은 다양한 형태로 발전해 왔으며, 챗GPT와 같은 생성형 AI 기반 가상 비서의 등장과 함께 발전하고 있지만 개인 정보 보호와 같은 과제도 존재한다. - 인공지능의 응용 - 질의 응답
질의응답 시스템은 자연어 질문을 이해하고 답변을 생성하며, 질문 유형과 사용 기술에 따라 분류되고, 읽기 이해 기반 또는 사전 지식 기반으로 작동하며, 대규모 언어 모델과 다양한 아키텍처 발전에 힘입어 복잡한 질문에 대한 답변과 다양한 분야에 활용이 가능해졌다.
| 기계 번역 | |
|---|---|
| 지도 | |
| 기본 정보 | |
| 유형 | 자동 번역의 하위 분야 |
| 설명 | 컴퓨터 소프트웨어를 사용하여 텍스트를 한 언어에서 다른 언어로 자동 변환하는 과정 |
| 다른 이름 | 자동 번역 |
| 관련 분야 | 전산 언어학, 자연어 처리 |
| 역사 | |
| 초기 아이디어 | 17세기 |
| 공식적인 연구 시작 | 1940년대 후반 |
| 초창기 방법 | 규칙 기반 방법 |
| 1950년대 발전 | 조지타운-IBM 실험 |
| 1960년대 연구 | 큰 좌절 |
| 1980년대 발전 | 통계 기반 기계 번역, 예시 기반 기계 번역 |
| 2010년대 발전 | 심층 학습 기반 기계 번역 |
| 방법론 | |
| 규칙 기반 기계 번역 (RBMT) | 언어 규칙에 기반하여 번역 형태소 분석, 구문 분석 사용 사전, 문법 규칙 사용 |
| 통계 기반 기계 번역 (SMT) | 통계 모델을 사용하여 번역 코퍼스에서 번역 학습 단어 및 구문 확률 분석 구문 기반 SMT, 계층적 SMT |
| 예시 기반 기계 번역 (EBMT) | 번역 예시를 이용하여 번역 저장된 번역 패턴 매칭 기존 번역을 재사용 |
| 신경망 기계 번역 (NMT) | 심층 신경망을 사용하여 번역 인공 신경망 기반 순환 신경망, 트랜스포머 모델 사용 문맥 정보를 잘 포착 |
| 성능 및 평가 | |
| 정확도 | 완벽한 번역이 어려운 경우가 많음 |
| 평가 방법 | 사람 평가 BLEU 점수 등 자동 평가 지표 |
| 발전 방향 | 번역 품질 향상 어휘 및 문법 다양성 처리 문맥 이해 능력 향상 |
| 활용 | |
| 웹 번역 | 구글 번역, 네이버 파파고 등 |
| 전문 번역 지원 | 번역가 작업 지원 |
| 다국어 커뮤니케이션 | 실시간 다국어 소통 도구 |
| 자동 자막 생성 | 영상 번역 및 자막 제작 |
| 지역화 | 소프트웨어, 웹사이트 등 지역화 |
| 장단점 | |
| 장점 | 빠르고 편리 비용 효율적 대량 번역 가능 |
| 단점 | 문맥 및 뉘앙스 이해 부족 번역 품질의 불균일성 오류 발생 가능성 |
| 기술 발전 | |
| 심층 학습 발전 | 번역 품질이 크게 향상됨 |
| 인공지능 결합 | 더 나은 번역 결과 제공 |
| 실시간 번역 기능 | 즉각적인 번역 제공 |
| 관련 연구 | |
| 주요 연구 분야 | 번역 품질 평가 어휘 및 문법 분석 문맥 및 뉘앙스 처리 저자 인지 기계 학습 알고리즘 개선 사용성 및 접근성 향상 |
| 연구 방향 | 사람 수준의 번역 목표 다국어 및 다중 모델 지원 편견 감소 및 공정성 확보 |
| 추가 정보 | |
| 참고 자료 | IEEE 스펙트럼 - 구글 번역 심층 학습 업그레이드 |
| 관련 기사 | PCMag UK - 구글 번역 vs ChatGPT: 누가 최고의 언어 번역기인가? |
2. 역사
초창기 기계 번역은 규칙 기반(RBMT, Rule-Based Machine Translation) 기술을 주로 사용했다. 규칙 기반 기술은 언어의 문법을 규칙화하여 번역하는 방식으로, 언어학자가 개발 과정의 중심이 되어야 했다. 규칙 기반 기계 번역은 문법에 기초하여 정확성이 높았지만, 개발 시간과 비용이 많이 들어 시스트란과 같은 번역 전문 대기업만이 할 수 있는 분야였다.[99]
1988년 IBM이 통계 기반(SMT, Statistical Machine Translation) 기술을 기계 번역에 도입하면서 혁신적인 변화가 일어났다. 통계 기반 기술은 방대한 양의 연구 자료, 즉 빅데이터를 이용해 통계적으로 규칙을 생성하여 번역하는 방식이다. 언어학자 없이도 개발이 가능하고 데이터가 많이 쌓일수록 번역 품질이 향상되는 장점이 있지만, 반대로 대량의 데이터가 쌓이기 전까지는 번역 품질이 떨어진다는 단점이 있다.[99]
통계 방식의 기계 번역 도입 이후, 언어 데이터를 다루는 검색 엔진 기업 등 글로벌 IT 기업들이 기계 번역 개발에 뛰어들 수 있게 되었다. 최근에는 규칙 기반 기계 번역도 통계 기반 기술을 함께 사용하는 하이브리드 방식으로 진화하고 있다.[99]
기계 번역이라는 개념은 20세기 중반에 등장했다. 워렌 위버(섀넌의 논문 『통신의 수학적 이론』의 책판 공저자)가 1947년 3월 노버트 위너에게 보낸 편지에서 러시아어로 쓰인 글을 “암호화된 영어 글”로 간주하여 암호 해독으로 기계 번역을 제안했다. 그러나 같은 해 4월 위너는 자연어는 모호한 표현이 많아 암호 해독처럼 잘 되지 않을 것이라고 회의적인 답장을 보냈다.
미국과 소련의 경우, 기계 번역은 냉전을 배경으로 한 수요가 있었다. 한편 유럽의 경우, 다국간 협상이나 조약에서 다국어 간 번역이라는 과제를 안고 있었다. 일본의 경우, 영어-일본어, 일본어-영어 번역이 요구되었다.
1954년 조지타운 대학교 연구 그룹이 기계 번역 성과를 발표했다. 일본에서는 1950년대에 규슈 대학의 쿠리하라 토시히코 등이 연구를 시작하여 1950년대 말에 실험 기계 “KT-1”을[76], 전기 시험소(후의 전자 기술 종합 연구소) 연구팀이 실험 기계 “야마토”를[77] 제작했다. 1964년 미국의 ALPAC 보고서에서 실용 수준에 미치지 못한다고 판단하여 미국에서는 한동안 연구가 정체되었다. 1980년대가 되면 규칙 기반 기계 번역 시스템이 일정한 성과를 거두게 되었다.
1990년대부터 2000년대에 걸쳐 인공 지능 개발이 정체되면서 기계 번역의 정확성에 대한 여러 우려가 제기되었다. 그러나 맨체스터 대학의 아나 니뇨 박사는 “나쁜 본보기로서의 기계 번역 (''MT as Bad Model'')”[78] 연구를 통해 기계 번역 이용의 장점을 조사했다. 이 교육 방법은 학습자에게 번역의 부정확한 측면을 인식시켜 언어 이해도를 높이는 효과가 있었다.[76]
IBM은 1990년대에 “IBM 모델”이라는 통계적 방법을 제안했다. 이것이 통계적 기계 번역의 시작이다. 2000년대에는 구문 구조를 이용한 번역 방법이 발표되면서 어족이 다른 언어 간 번역 정확도가 향상되었다.
2010년대에는 뉴럴 네트워크에 의한 딥 러닝을 사용한 뉴럴 기계 번역(NMT)이 등장하면서 품질이 향상되었다.[79] 2010년대 후반에는 AI의 딥 러닝 기술 발전으로 특정 용도 번역에서 사람의 보조를 통해 어느 정도 해결책이 보이게 되었고, 일상생활에서의 의사소통에 큰 영향을 줄 것으로 기대되었다.[80]
정보통신연구기관에 따르면, 2021년 현재 인공 지능은 음성 인식 능력에서 인간을 능가하지만, 정확도와 속도에는 과제가 있다. 현재 기계 번역은 문장 단위로만 번역 가능하여 10초 정도의 시간 지연이 발생한다. 의미 단위로 번역하는 “청크” 기능과 “수정 기능”이 개발 중이며, “GPT-3” 기능 응용 등이 연구되고 있지만, “일직선으로 현재 성과는 나오지 않고 있다”는 비판도 있다.[81]
2021년 4월, NVIDIA는 실시간 다국어 음성 인식 및 번역 가능 인공 지능 프레임워크 “Jarvis”를 공개했다.[82] 2022년 11월에는 대규모 언어 모델에 의한 chatGPT가 등장하여 기계 번역 업계 상황이 크게 변화했다.
2. 1. 기원
초창기 기계 번역은 주로 규칙 기반(RBMT, Rule-Based Machine Translation) 기술을 사용했다. 규칙 기반 기술은 언어의 문법을 규칙화하여 번역하는 방식으로, 언어학자가 개발 과정의 중심이 되어야 했다. 규칙 기반 기계 번역은 문법에 기초하여 정확성이 높았지만, 개발 시간과 비용이 많이 들어 시스트란과 같은 번역 전문 대기업만이 할 수 있는 분야였다.[99]이후 1988년 IBM이 통계 기반(SMT, Statistical Machine Translation) 기술을 기계 번역에 도입하면서 혁신적인 변화가 일어났다. 통계 기반 기술은 방대한 양의 연구 자료, 즉 빅데이터를 이용해 통계적으로 규칙을 생성하여 번역하는 방식이다. 언어학자 없이도 개발이 가능하고 데이터가 많이 쌓일수록 번역 품질이 향상되는 장점이 있지만, 반대로 대량의 데이터가 쌓이기 전까지는 번역 품질이 떨어진다는 단점이 있다.[99]
통계 방식의 기계 번역 도입 이후, 검색 엔진 기업 등 글로벌 IT 기업들이 기계 번역 개발에 뛰어들 수 있게 되었다. 최근에는 규칙 기반 기계 번역도 통계 기반 기술을 함께 사용하는 하이브리드 방식으로 진화하고 있다.[99]
기계 번역의 기원은 9세기 아랍의 암호학자 알킨디의 연구로 거슬러 올라간다. 그는 암호 해독, 빈도 분석, 그리고 현대 기계 번역에 사용되는 확률과 통계를 포함한 체계적인 언어 번역 기술을 개발했다.[3] 1629년, 르네 데카르트는 서로 다른 언어의 동등한 개념들이 하나의 기호를 공유하는 보편 언어를 제안했다.[4]
1947년 영국의 A. D. 부스[5]와 록펠러 재단의 워렌 위버가 자연어 번역에 디지털 컴퓨터를 사용하자는 아이디어를 제안했다. "1949년 워렌 위버가 작성한 메모는 아마도 기계 번역 초기의 가장 영향력 있는 단일 출판물일 것입니다."[6][7] 1954년 버크벡 칼리지(런던대학교)의 APEXC 기계를 이용하여 영어를 프랑스어로 번역하는 기초적인 시연이 이루어졌다.
기계 번역이라는 개념은 20세기 중반에 등장했다. 워렌 위버(섀넌의 논문 『통신의 수학적 이론』의 책판 공저자)가 1947년 3월 노버트 위너에게 보낸 편지에서 러시아어로 쓰인 글을 “암호화된 영어 글”로 간주하여 암호 해독으로 기계 번역을 제안했다. 그러나 같은 해 4월 위너는 자연어는 모호한 표현이 많아 암호 해독처럼 잘 되지 않을 것이라고 회의적인 답장을 보냈다.
미국과 소련의 경우, 기계 번역은 냉전을 배경으로 한 수요가 있었다. 한편 유럽의 경우, 다국간 협상이나 조약에서 다국어 간 번역이라는 과제를 안고 있었다. 일본의 경우, 영어-일본어, 일본어-영어 번역이 요구되었다.
대학 및 연구 기관의 성과 중 가장 빠른 것은 1954년 조지타운 대학교 등의 연구 그룹이 발표한 것이다. 일본에서는 1950년대에 규슈 대학의 쿠리하라 토시히코 등이 연구를 시작하여 1950년대 말에 실험 기계 “KT-1”을[76], 또한 전기 시험소(후의 전자 기술 종합 연구소)의 연구팀이 실험 기계 “야마토”를[77] 제작했다. 미국의 ALPAC 보고서(1964)에서 실용 수준에는 멀었다고 판단됨에 따라 미국에서는 한동안 연구가 정체되었다. 1980년대가 되면 규칙 기반의 기계 번역 시스템이 일정한 성과를 거두게 되었다.
2. 2. 초기 연구 (1950년대 ~ 1960년대)
기계 번역에 관한 초기 아이디어는 17세기에 등장했다. 1629년, 르네 데카르트는 서로 다른 언어에서 같은 개념을 하나의 기호로 나타내는 보편 언어를 제안했다.[4]1947년, 영국의 A. D. 부스[5]와 록펠러 재단의 워렌 위버[6][7]는 자연어를 번역하는 데 디지털 컴퓨터를 활용하자는 아이디어를 제안했다. 1954년에는 버크벡 칼리지(런던대학교)에서 APEXC 기계를 사용해 영어를 프랑스어로 번역하는 기초적인 시연이 이루어졌다.
1951년, 예호슈아 바르-힐렐이 MIT에서 기계 번역 연구를 시작했다. 1954년, 조지타운 대학교 기계 번역 연구팀은 조지타운-IBM 실험 시스템을 공개 시연했다. 일본[8][9]과 소련(1955년)에서도 기계 번역 연구 프로그램이 시작되었고, 1956년에는 런던에서 최초의 기계 번역 컨퍼런스가 개최되었다.[10][11]
데이비드 G. 헤이스는 1957년 초에 컴퓨터를 이용한 언어 처리에 대해 저술했으며, 1955년부터 1968년까지 RAND사에서 전산 언어학 프로젝트를 이끌었다.[12]
2. 3. 발전과 정체 (1970년대 ~ 1980년대)
초창기 기계 번역은 주로 규칙 기반(RBMT, Rule-Based Machine Translation) 기술을 사용했다. 규칙 기반 기술은 언어의 문법을 규칙화하여 번역하는 방식으로, 언어학자가 중심이 되어 개발해야 했다.[99] 규칙 기반 기계 번역은 문법에 기초한 알고리즘 덕분에 정확도가 높았지만, 개발 시간과 비용이 많이 들어 시스트란과 같은 번역 전문 대기업만이 할 수 있는 분야였다.[99]1988년 IBM이 통계 방식(SMT, Statistical Machine Translation) 기술을 기계 번역에 도입하면서 혁신적인 변화가 일어났다. 통계 기반 기술은 방대한 양의 연구 자료(빅데이터)를 이용해 통계적으로 규칙을 생성하여 번역한다. 통계 기반 기계 번역은 언어학자 없이도 개발할 수 있고 데이터가 많이 쌓일수록 번역 품질이 향상된다는 장점이 있지만, 반대로 대량의 데이터가 쌓이기 전까지는 번역 품질이 떨어진다는 단점이 있다.[99]
통계 방식 기계 번역의 도입으로 언어 데이터를 다루는 검색 엔진 기업 등 글로벌 IT 기업들이 기계 번역 개발에 뛰어들 수 있게 되었다. 최근에는 규칙 기반 기계 번역도 통계 기반 기술을 함께 사용하는 하이브리드 방식으로 진화하고 있다.[99]
1970년대 후반, 제록스는 시스트란(SYSTRAN)을 사용하여 기술 설명서를 번역했다. 1980년대 후반부터 컴퓨팅 성능이 향상되고 가격이 저렴해짐에 따라 통계 기계 번역 모델에 대한 관심이 높아졌다.
2. 4. 통계 기반 및 신경망 기반 번역 (1990년대 이후)
1990년대부터 IBM이 통계 방식(SMT, Statistical Machine Translation)을 기계 번역에 도입하면서 혁신적인 변화가 일어났다. 통계 기반 기술은 방대한 양의 연구 자료, 즉 빅데이터를 이용해 통계적으로 규칙을 생성해 번역하는 방법이다. 통계 기반 기계 번역은 언어학자 없이도 개발할 수 있고 데이터가 많이 쌓일수록 번역 품질이 향상된다는 장점이 있지만, 대량의 데이터가 쌓이기 전까지는 번역 품질이 떨어진다는 단점이 있다.[99]통계 방식 기계 번역 도입 이후, 언어 데이터를 다루는 검색 엔진 기업 등 글로벌 IT 기업들이 기계 번역 개발에 뛰어들 수 있게 되었다. 최근에는 규칙 기반 기계 번역도 통계 기반 기술을 함께 사용하는 하이브리드 방식으로 진화하고 있다.[99]
1980년대 후반부터 컴퓨팅 성능이 향상되고 가격이 저렴해짐에 따라 통계 기계 번역 모델에 대한 관심이 높아졌다. 컴퓨터의 등장 이후 기계 번역은 더욱 대중화되었다.[15]
프란츠 요제프 오흐(Franz Josef Och)(구글 번역 개발팀의 미래 책임자)는 2003년 DARPA의 고속 기계 번역 대회에서 우승했다.[19] 2012년 구글은 구글 번역이 하루에 약 100만 권의 책에 해당하는 분량의 텍스트를 번역한다고 발표했다.
한편, IBM은 1990년대에 서로 다른 언어 간의 단어 대응을 통계적으로 얻는 “IBM 모델”이라는 방법을 제안했다. 이것이 통계적 기계 번역의 시작이다. 초기 통계적 기계 번역은 단어의 배열을 기반으로 한 것이었지만, 2000년대에 구문 구조를 이용한 번역 방법이 발표되면서 어족이 다른 언어 간에도 번역의 정확도가 비약적으로 향상되었다.
2010년대에 들어와 문장 번역에의 응용은 불가능하다고 여겨졌던 뉴럴 네트워크에 의한 딥 러닝을 사용한 뉴럴 기계 번역(NMT)이 등장하면서 품질이 향상되었다.[79]
2. 5. 한국어 기계 번역의 역사
초창기 기계 번역은 규칙 기반(RBMT, Rule-Based Machine Translation) 기술을 이용한 것이 주류였다. 규칙 기반 기술은 언어의 문법을 규칙화해 번역하는 방법으로, 개발 과정에서 언어학자가 중심이 되어야 구축이 가능한 번역 기술이었다. 규칙 기반 기계 번역은 알고리즘의 기초를 문법에 두기 때문에 정확성이 매우 높다는 장점이 있었으나, 개발 시간과 비용이 많이 들기 때문에 시스트란과 같은 번역 전문 대기업만 할 수 있는 분야였다.[99]이후 1988년 IBM이 통계 방식(SMT, Statistical Machine Translation) 기술을 기계 번역에 도입하면서 혁신적인 변화가 일어났다. 통계 기반 기술은 방대한 양의 연구 자료, 즉 빅데이터를 이용해 통계적으로 규칙을 생성해 번역하는 방법이다. 통계 기반의 기계 번역은 언어학자 없이도 개발을 할 수 있고 데이터가 많이 쌓일수록 번역의 품질이 높다는 장점이 있으며, 반대로 대량의 데이터가 쌓이기 전까지는 번역의 품질이 떨어진다는 단점이 있다.[99]
통계 방식의 기계 번역이 도입된 이후, 언어 데이터를 다루는 검색 엔진 기업 등의 글로벌 IT 기업들이 기계 번역 개발에 뛰어들 수 있게 됐다. 최근에는 규칙 기반 기계 번역도 통계 기반 기술을 함께 사용하는 하이브리드 방식으로 진화 중이다.[99]
3. 접근 방식
기계 번역의 접근 방식은 크게 규칙 기반 기계 번역(RBMT)과 말뭉치 기반 방식으로 나뉜다. 말뭉치 기반 방식에는 통계 기계 번역(SMT)과 신경망 기계 번역(NMT)이 있으며, 2010년 이후로는 신경망 기계 번역이 주류가 되었다.[79]
기계 번역의 기원은 9세기 아랍의 암호학자 알킨디의 연구로 거슬러 올라간다. 그는 암호 해독, 빈도 분석 등 현대 기계 번역에 사용되는 확률과 통계를 포함한 체계적인 언어 번역 기술을 개발했다.[3] 1629년, 르네 데카르트는 서로 다른 언어의 개념들이 하나의 기호를 공유하는 보편 언어를 제안했다.[4]
1947년 영국의 A. D. 부스[5]와 워렌 위버는 자연어 번역에 디지털 컴퓨터를 사용하자는 아이디어를 제안했다.[6][7] 1954년 버크벡 칼리지에서 APEXC 기계를 이용해 영어를 프랑스어로 번역하는 기초적인 시연이 이루어졌다.
심층 학습 방법이 등장하기 전에는 통계적 방법에 많은 규칙과 함께 형태론적, 구문론적, 의미론적 주석이 필요했다.
용례 기반 번역은 데이터베이스가 전체 문장을 기억하는 방식이다. 반면, 단어·구절 기반 번역은 문장을 작은 단위로 나누고 출현 확률이나 배열 확률 등의 정보를 이용해 코퍼스에 없는 문장에 대한 일반화 능력을 높인다.
3. 1. 규칙 기반 기계 번역 (RBMT)
초창기 기계 번역은 주로 규칙 기반(RBMT, Rule-Based Machine Translation) 기술을 사용했다. 이 방식은 언어의 문법을 규칙화하여 번역하는 방식으로, 언어학자가 개발 과정의 중심이 되어야 했다. 규칙 기반 기계 번역은 문법에 기초하여 정확성이 높다는 장점이 있었지만, 개발 시간과 비용이 많이 들어 시스트란과 같은 번역 전문 대기업만이 할 수 있는 분야였다.[99]규칙 기반 기계 번역 방식은 주로 사전과 문법 프로그램을 만드는 데 사용되었으며, 모든 것을 명시적으로 만들어야 한다는 단점이 있었다. 즉, 철자 변형과 잘못된 입력을 처리하기 위해서는 원어 분석기에 이를 포함시켜야 했고, 모호성이 있는 모든 경우에 대해 어휘 선택 규칙을 작성해야 했다.
1988년 IBM이 통계 방식(SMT, Statistical Machine Translation) 기술을 기계 번역에 도입하면서 혁신적인 변화가 일어났다. 최근에는 규칙 기반 기계 번역도 통계 기반 기술을 함께 사용하는 하이브리드 방식으로 진화하고 있다.[99]
3. 1. 1. 전이 기반 기계 번역
전이 기반 기계 번역은 중간 언어 기계 번역과 유사하게, 원문의 의미를 시뮬레이션하는 중간 표현에서 번역을 생성한다. 중간 언어 기계 번역과 달리, 번역에 관련된 언어 쌍에 부분적으로 의존한다.[3]구문 트리 기반 번역은 기계 번역 개발 초기부터 있었던 아이디어이다. 단어·구절 기반 번역은 문장의 구조를 이용하지 않기 때문에 문법적으로 잘못된 번역이 많았다. 또한, 일한 번역처럼 단어의 배열 순서 차이가 큰 경우, 정확한 번역을 하려고 하면 탐색 공간이 기하급수적으로 커지는 문제가 있었다. 구문 트리 기반 번역에서는 입력 문장의 구문 정보를 이용하여, 언어 구조적으로 잘못된 배열 순서를 탐색 공간에서 제외하고, 더 정확한 번역을 할 수 있을 것으로 기대되었다. 그러나 이 구문 트리에 의존하는 번역 시스템은 많은 연구자들에 의한 오랜 시행착오에도 불구하고, 결국 번역문의 질이 실용 번역, 실용 통역의 수준까지 향상되지 못하고 난항을 겪었다.
구문 트리 기반 기법에는 여러 가지가 있지만, 구문 구조 기반 번역의 한 예시는 다음과 같다.
# 원문 를 구문 분석한다.
# 얻어진 구문 트리를, 정해진 규칙에 따라 부분 트리별로 변환하여, 역문 의 구문 트리를 얻는다.
# 변환한 구문 트리에서 역문을 생성한다.
예를 들어, 영어에서 한국어로의 번역에서 "I have a pen."이라는 원문이 주어졌을 때, 이 문장을 구문 분석하여 얻어지는 구문 트리는 다음과 같다.
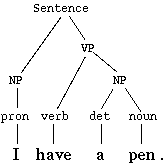
다음 사전을 사용하여 영어 단어를 한국어 단어로 바꾼다.
| 영어 | 한국어 |
|---|---|
| I | 나 |
| have | 가지고 있다 |
| a | (공백) |
| pen | 펜 |
구문 트리는 다음과 같다.
(S (NP (pron 나)) (VP (verb 가지고 있다) (NP (det -) (noun 펜))))
하지만 아직 어순이 옳지 않고, 조사도 없다. 여기서 구문 트리에 다음과 같은 규칙을 적용하여 변환한다.
- "S → ''NP'' ''VP''"라는 노드가 있으면, 그것을 "S → ''NP''는 ''VP''"로 변환하라.
- "VP → ''verb'' ''NP''"라는 노드가 있으면, 그것을 "VP → ''NP''를 ''verb''"로 변환하라.
그러면 변환된 트리는 다음과 같다.
(S (NP (pron 나))는 (VP (NP (det -) (noun 펜))을 (verb 가지고 있다)))
여기서, 다음과 같은 번역문을 생성할 수 있다.
"나는 펜을 가지고 있다."
이는 매우 단순한 예시이다. 실제로는 영어의 have는 여러 의미를 가지므로, 의미의 모호성 해소를 하지 않으면 단순히 “have → 가지고 있다”라는 변환을 할 수 없다. 또한, 모달 동사의 고려, 참조 해소, 존댓말 처리, 자연스러운 표현의 문장 생성 등, 실용적인 번역 소프트웨어를 만들기 위해서는 많은 것을 고려해야 한다.
구문 트리 기반 번역에서는 구문 분석 오류가 번역 결과에 악영향을 미치는 경우가 있다. 그 경우의 해결책으로, 여러 개의 구문 트리 후보(구문 숲)를 고려한 번역 기법도 있다.
3. 1. 2. 언어 중립적 기계 번역
언어 중립적 기계 번역은 규칙 기반 기계 번역 방식의 한 예이다. 이 방식에서는 번역할 텍스트인 원어를 어떤 언어에도 의존하지 않는 "언어 중립적" 표현인 중간 언어로 변환한다. 그런 다음 목표 언어는 중간 언어에서 생성된다. 상업적 수준에서 운영 가능하게 만들어진 유일한 언어 중립적 기계 번역 시스템은 캐터필러 기술 영어(CTE)를 다른 언어로 번역하도록 설계된 KANT 시스템(Nyberg and Mitamura, 1992)이었다.3. 1. 3. 사전 기반 기계 번역
사전 기반 기계 번역은 사전의 항목을 기반으로 하는 번역 방법으로, 단어가 사전에 있는 그대로 번역된다는 것을 의미한다.3. 2. 통계 기반 기계 번역 (SMT)
초창기 기계 번역은 규칙 기반(RBMT, Rule-Based Machine Translation) 기술을 이용한 것이 주류였다. 규칙 기반 기술은 언어의 문법을 규칙화해 번역하는 방법으로, 개발 과정에서 언어학자가 중심이 되어야 구축이 가능한 번역 기술이었다. 규칙 기반 기계 번역은 알고리즘의 기초를 문법에 두기 때문에 정확성이 매우 높다는 장점이 있었으나, 개발 시간과 비용이 많이 들기 때문에 시스트란과 같은 번역 전문 대기업만 할 수 있는 분야였다.[99]이후 1988년 IBM이 통계 방식(SMT, Statistical Machine Translation) 기술을 기계 번역에 도입하면서 혁신적인 변화가 일어났다. 통계 기반 기술은 방대한 양의 연구 자료, 즉 빅데이터를 이용해 통계적으로 규칙을 생성해 번역하는 방법이다. 통계 기반 기계 번역은 언어학자 없이도 개발을 할 수 있고 데이터가 많이 쌓일수록 번역의 품질이 높다는 장점이 있으며, 반대로 대량의 데이터가 쌓이기 전까지는 번역의 품질이 떨어진다는 단점이 있다.[99]
통계 방식 기계 번역이 도입된 이후, 언어 데이터를 다루는 검색 엔진 기업 등의 글로벌 IT 기업들이 기계 번역 개발에 뛰어들 수 있게 됐다. 최근에는 규칙 기반 기계 번역도 통계 기반 기술을 함께 사용하는 하이브리드 방식으로 진화 중이다.[99]
통계적 기계 번역은 캐나다 한사드(Canadian Hansard) 자료(캐나다 의회의 영어-프랑스어 의사록)나 유로파르(EUROPARL)(유럽 의회 의사록)와 같은 이중 언어 텍스트 말뭉치를 기반으로 통계적 방법을 사용하여 번역을 생성하려고 시도했다. 이러한 말뭉치가 있을 경우 유사한 텍스트를 번역하는 데 좋은 결과를 얻었지만, 많은 언어 쌍에 대해서는 그러한 말뭉치가 드물었다. 최초의 통계적 기계 번역 소프트웨어는 IBM의 캔디드(CANDIDE)였다. 2005년 구글은 유엔 자료의 약 2천억 단어를 사용하여 자체 시스템을 훈련시킴으로써 내부 번역 기능을 개선했고, 번역 정확도가 향상되었다.[20]
SMT의 가장 큰 단점은 방대한 양의 병렬 텍스트에 의존해야 한다는 점, 형태소가 풍부한 언어(특히 이러한 언어로 ''번역하는 경우'')에 대한 문제, 그리고 단일 오류를 수정할 수 없다는 점이었다.
3개 이상의 언어로 번역된 텍스트 집합인 다중 병렬 말뭉치를 활용하는 연구가 진행되었다. 이러한 방법을 사용하면 2개 이상의 언어로 번역된 텍스트를 결합하여 단일 소스 언어만 사용하는 경우보다 세 번째 언어로의 보다 정확한 번역을 제공할 수 있다.[21][22][23]
용례 기반 번역에서는 데이터베이스가 전체 문장을 기억했다. 반면, 단어·구절 기반 번역에서는 문장을 작은 단위로 나누고, 출현 확률이나 배열 확률과 같은 정보를 이용함으로써, 코퍼스에 존재하지 않는 문장에 대한 일반화 능력을 높인다.
1990년대 이후 컴퓨터의 발달에 따라 통계적인 방법을 이용한 기계 번역이 활발하게 연구되고 있다. 규칙 기반 번역에서는 사람이 만든 규칙을 벗어나는 입력 문장에는 대응할 수 없는 문제가 있었다. 또한 번역 규칙의 작성과 검토에는 막대한 노력이 필요하므로 비효율적이다. 그래서 통계적 기계 번역에서는 병렬 코퍼스(parallel corpus)라고 불리는, 여러 언어로 문장 간의 대응이 붙은 코퍼스를 이용하여 번역 규칙을 자동으로 획득하고 각 규칙의 중요도를 통계적으로 추정한다. 병렬 코퍼스에는 자체 데이터를 사용할 수도 있지만, 최근에는 각 언어로 번역된 특허나 웹 페이지 크롤링 데이터 등을 사용하는 경우도 있다.
통계적 기계 번역은 기존 음성 인식 분야에서 사용되던 잡음 채널 모델을 응용한 것이다. 원언어(번역 원본 언어) ''는 목표 언어(번역 후 언어) ''가 잡음이 있는 통신 채널을 통과하는 동안 변화한 것으로 간주하고, 번역 작업을 원언어에서 목표 언어로의 복호화라고 생각한다. 잡음 채널 모델에서는 복호 오류가 가장 작아지는 번역 결과 는 다음 식을 만족한다.
:
두 번째 변형은 베이즈 정리에 의한 것이다. 여기서 를 모델화한 것을 언어 모델, 를 모델화한 것을 번역 모델이라고 부르며, 언어 모델은 번역 결과의 언어적 유창성을, 번역 모델은 번역의 타당성을 모델링하고 있다고 할 수 있다. 번역 모델만으로는 목표 언어로서 올바르지 않은 문장이 되어 버리므로, 언어 모델에 의해 목표 언어로서 올바르지 않은 문장을 제거할 수 있다고 생각된다. 또한, 언어 모델에 대한 연구는 음성 인식 등의 분야에서 이미 연구가 진행되고 있으며, 그 지식을 활용할 수도 있다.
통계적 기계 번역의 처리 시스템은 이러한 모델의 조합이 높은 값을 주는 번역 결과를 탐색하게 된다. 이러한 처리 시스템은 암호 이론으로부터의 유추로 디코더(복호기)라고 불린다.
2000년대부터 구절 기반 통계적 기계 번역을 시작으로 활발하게 연구되고 있으며, 최근에는 직접 잡음 채널 모델을 사용하는 것이 아니라, 최대 엔트로피 방법(로그 선형 모델)에 기반한 아래의 최적화 문제로 생각하는 경우가 많다.
:
통계 번역에서도 번역의 정확도를 높이기 위해 사람에 의해 추가된 규칙을 이용하는 경우가 있다. 또한, 최근에는 병렬이 아닌 코퍼스에서 번역 규칙을 얻는 연구도 이루어지고 있다.[91]
3. 3. 신경망 기계 번역 (NMT)
심층 학습 기반의 기계 번역(MT) 방식인 신경망 기계 번역은 최근 몇 년 동안 빠르게 발전했다. 기계 번역 기법은 크게 "규칙 기반 기계 번역(RBMT)"과 "말뭉치 기반 방식"으로 나뉘며,[90] 말뭉치 기반 방식에는 "통계 기계 번역(SMT)"과 "신경망 기계 번역(NMT)"이 있다.[79] 2010년 이후로는 신경망 기계 번역이 주류가 되었다.[79]DeepL Translator와 같은 신경망 기계 번역 도구의 번역은 일반적으로 여전히 사람이 사후 편집해야 한다.[26][27][28]
병렬 데이터 세트에서 특수 번역 모델을 학습하는 대신, 프롬프트를 직접 사용하여 GPT와 같은 생성형 대규모 언어 모델에 텍스트 번역을 지시할 수도 있다.[29][30][31] 이러한 접근 방식은 유망하게 여겨지지만,[32] 여전히 특수 번역 모델보다 자원 집약적이다.
3. 4. 예시 기반 기계 번역
예시 기반 기계 번역은 규칙 기반 기계 번역(RBMT)과 말뭉치 기반 방식 중 하나이다.[90] 특허나 매뉴얼 등 문장 스타일이 거의 변하지 않는 상황에서는 일반화 능력이 작더라도 시스템으로서 충분히 기능하는 경우가 있다. 예시 기반 번역에서는 번역 예문을 기억한 "용례 사전"과 단어 대응을 기억한 "단어 사전"을 사용한다.시스템의 대략적인 흐름은 다음과 같다.
1. 시스템에 원문 가 주어진다.
2. 용례 사전에서 와 비슷한 문장 와 그 짝 를 검색한다.
3. 시스템은 와 의 차분을 취한다.
4. 번역문 내의 적절한 단어를 단어 사전을 이용하여 바꾼다.
5. 바꾼 결과를 번역 결과로 출력한다.
예시 기반 번역에서는 데이터베이스가 전체 문장을 기억한다. 반면, 단어·구절 기반 번역에서는 문장을 작은 단위로 나누고, 출현 확률이나 배열 확률과 같은 정보를 이용함으로써, 코퍼스에 존재하지 않는 문장에 대한 일반화 능력을 높인다.
3. 5. 대규모 언어 모델 (LLM) 방식
대규모 언어 모델(LLM)을 활용한 AI인 챗GPT의 등장은 기계 번역 분야에 혁신을 가져왔다.[92]챗GPT는 인간 통역관에게 지시하는 것처럼 자연어로 명령을 내릴 수 있으며, 프롬프트를 통해 다양한 유형의 번역 결과물을 생성할 수 있다. 예를 들어, 특정 단어가 사용되는 문맥을 설정하고 그에 맞는 번역을 지시하는 것이 가능하다.
GPT와 같은 생성형 대규모 언어 모델은 별도의 병렬 데이터 세트 없이도 프롬프트를 통해 텍스트 번역을 수행할 수 있다.[29][30][31] 이러한 접근 방식은 가능성을 보여주고 있지만,[32] 특화된 번역 모델에 비해 더 많은 자원을 필요로 한다.
4. 주요 과제
기계 번역은 초기부터 여러 난제에 직면했다. 1970년대 후반, 제록스는 시스트란(SYSTRAN)을 사용해 기술 문서를 번역했고,[14] 1980년대 후반에는 컴퓨팅 성능 향상으로 통계 기계 번역 모델이 주목받았다.[15] 1988년 프랑스 우정청은 미니텔을 통해 시스트란 서비스를 제공했으며,[16] 트라도스는 번역 메모리 기술(1989년)을 개발했지만 기계 번역과는 다르다. 하르키우 국립대학교는 최초의 상용 기계 번역 시스템(러시아어/영어/독일어-우크라이나어)을 개발했다(1991년).
1998년에는 PC용 단방향 번역 프로그램(영어-주요 유럽 언어)이 29.95달러에 판매되었다.[14] 1996년 시스트란은 바벨피시를 통해 무료 텍스트 번역을 제공했고,[14] 1997년에는 하루 50만 건을 처리했다.[17] 러너우트 앤 하우스피(Lernout & Hauspie)의 글로벌링크도 무료 번역 서비스를 제공했다.[14] 1998년 ''애틀랜틱 매거진''은 시스트란과 글로벌링크가 "Don't bank on it"을 "능숙하게" 처리했다고 보도했다.[18]
2003년 프란츠 요제프 오흐(구글 번역 개발팀 책임자)는 DARPA 대회에서 우승했다.[19] 오픈소스 통계 기계 번역 엔진(2007년), 일본의 휴대폰용 문자/SMS 번역(2008년), 음성-음성 번역 휴대폰(영어, 일본어, 중국어, 2009년) 등이 혁신 사례다. 2012년 구글은 구글 번역이 하루 100만 권 분량의 텍스트를 번역한다고 발표했다.

전문 번역가 등의 평가에 따르면, 최신 기계 번역도 여러 문제점을 보인다.[31] 상식, 맥락, 원문 오류, 교육 데이터 부족 등이 문제이며, 인간의 적극적 참여가 필요하다.[31]
자연어 문장은 기계 번역의 어려움 중 하나다. 구문론 외에 상식, 의미론도 고려해야 한다. 예를 들어 "Time flies like an arrow."는 "시간은 화살처럼 빨리 지나간다", "시간 파리는 화살을 좋아한다", "파리들을 계시하라! 화살처럼(빨리)!" 등 여러 번역이 가능하다. 사람은 의미론, 상식, 경험으로 번역문을 선택하지만, 기계는 현실 세계의 상식, 정상적인 문장과 비교하여 오역을 제거해야 한다. "시간은 화살처럼 빨리 지나간다"를 선택하려면 "사람은 시간이 빨리 간다고 느낀다", "화살은 빠르다", "'시간 파리'는 일상 대화에 없다" 등의 경험이 필요하다. 한국어 속담 "세월이 화살과 같다"는 지식도 유용하다.
1975년 예호슈아 바르 힐렐은 현실적인 기계 번역으로 다음을 제시했다.
- 기계 지원 인간 번역
- 인간 지원 기계 번역
- 저품질 기계 번역
오쿠무라 마나부(2014)는 "번역은 인간에게도 부담이 큰 작업이며, '전자동 고품질 기계 번역'을 목표로 해선 안 된다"고 지적했다. 티에리 푸아보(2017)는 "기계 번역이 인간 번역을 대체하지 않는다. 목표도 아니고 바람직한 결과도 아니다"라고 말했다.
「인공지능 대체 가능 직업」(노무라 종합연구소)에서 "번역 통역"은 범위 밖이다.[88] 「Frey and Osborne」(2013)은 번역 통역에 0.38 지표를 부여했다(1: 기계화 가능, 0.7~0.99: 미래 가능성 높음, 0.7 미만: 중간, 0.3 미만: 낮음).
딥러닝 기반 기계 번역 기술 향상으로, 규칙이 정해진 문서(특허, 법률, 논문 등)는 작성자가 "미리 기계 번역을 고려"하면 정확도가 높아질 것이다. 그러나 언어 복잡성으로 인한 한계도 지적된다. 니시다 소센카(2018)는 "중학생 수준 영어는 불필요", "번역가 실업 걱정 없음", "문화, 언어 뉘앙스 파악 AI는 먼 미래"라고 말했다.[89] AI는 단어 의미 자체 학습, 잘못된 학습 결과 포함, 비언어적/뉘앙스/감정 이해 불가 등의 이유 때문이다. 2020년에는 "완벽한 기계 번역은 비현실적"이라고 인식되었다.
한국어는 대명사("나", "이것") 생략이 잦아 기계 번역 시 보충해야 한다. "동생은 공원에 갔다. 거기서 친구를 만났다."에서 "He"를 추가해야 하지만, 문장 단위 번역은 어려움을 야기한다. 영어 "rice"는 "벼", "쌀", "밥"으로 번역될 수 있어, "We will have rice harvest tomorrow."를 "우리는 내일 벼 수확을 할 것이다."로 직역하면 어색하다.
4. 1. 중의성 해소
의미 분석(Word-sense disambiguation)은 하나의 단어가 여러 가지 의미를 가질 수 있을 때, 적절한 번역을 찾는 것을 의미한다. 이 문제는 1950년대 예호슈아 바르-힐렐에 의해 처음 제기되었다.[33] 그는 "범용 백과사전" 없이는 기계가 단어의 두 가지 의미를 구분할 수 없다는 점을 지적했다.[34]오늘날 이 문제를 해결하기 위해 고안된 수많은 접근 방식이 있다. 이러한 접근 방식은 대략 "표층적" 접근 방식과 "심층적" 접근 방식으로 나눌 수 있다. 표층적 접근 방식은 텍스트에 대한 지식을 전제하지 않고, 단순히 모호한 단어 주변의 단어에 통계적 방법을 적용한다. 반면 심층적 접근 방식은 단어에 대한 포괄적인 지식을 전제한다. 지금까지는 표층적 접근 방식이 더 성공적이었다.[35]
세계보건기구와 유엔에서 오랫동안 번역가로 일했던 클로드 피롱은 기계 번역이 번역가의 일 중 더 쉬운 부분을 자동화하는 데 가장 적합하다고 말했다. 그는 번역에서 더 어렵고 시간이 많이 걸리는 부분은 대개 원문의 모호한 부분을 해결하기 위한 광범위한 조사라고 설명했다. 이러한 모호성은 번역의 목표 언어의 문법적 및 어휘적 요구 사항에 따라 해결되어야 한다.
이상적인 심층적 접근 방식은 번역 소프트웨어가 이러한 종류의 의미 분석에 필요한 모든 조사를 스스로 수행하도록 요구한다. 하지만 이것은 아직 달성되지 않은 더 높은 수준의 인공지능을 필요로 한다. 피롱이 언급한 모호한 영어 구절의 의미를 단순히 추측하는 표층적 접근 방식(예를 들어, 주어진 말뭉치에서 어떤 종류의 포로 수용소가 더 자주 언급되는지에 따라)은 상당히 자주 잘못 추측할 가능성이 있다. "각 모호성에 대해 사용자에게 질문"하는 표층적 접근 방식은 피롱의 추정에 따르면 전문 번역가의 작업의 약 25%만 자동화하고, 더 어려운 75%는 여전히 사람이 해야 한다.
예를 들어 "Time flies like an arrow."라는 영어 문장의 경우, 의미 분석과 상식적 판단 없이는 여러 가지 번역 결과가 나올 수 있다. "시간은 화살처럼 빨리 지나간다" 외에도 "시간 파리는 화살을 좋아한다", "파리들을 계시하라! 화살처럼(빨리)!"과 같은 번역 결과까지 기계 번역 시스템이 출력할 수 있다.
단순한 구문 분석이나 문법 분석만으로는 여러 후보 번역문이 나올 수 있는 경우에도, 사람은 의미론과 상식, 그리고 과거의 언어적 경험을 활용하여 하나의 번역문을 선택한다. 기계 번역 시스템에서도 현실 세계의 상식과 현실 세계에 유통되는 많은 정상적인 문장과 비교하여 잘못된 번역문을 제거해야 하며, 이러한 판단을 기계 번역 시스템에 적용하는 알고리즘 등을 추가해야 한다.
"시간은 화살처럼 빨리 지나간다"라는 후보를 남기고 다른 후보를 제외하려면 "사람은 시간이 빨리 지나간다고 느낄 때가 있다", "화살은 빠르게 날아간다", "일상 대화에서 '시간 파리'와 같은 단어가 등장한 적이 없다" 등과 같은 언어적 경험이 필요하다.
"Time flies like an arrow."의 경우, 더 나아가 한국어에는 "세월이 화살과 같다"라는 속담이 있다는 지식을 사용하여 이에 도달하는 것이 좋다.
4. 2. 비표준어 처리
기계 번역의 주요한 문제점 중 하나는 표준어를 번역하는 것과 같은 정확도로 비표준어를 번역할 수 없다는 점이다. 휴리스틱 또는 통계 기반 기계 번역은 표준 형태의 언어로 된 다양한 출처의 입력을 받는다. 규칙 기반 번역은 본질적으로 일반적인 비표준 용법을 포함하지 않는다. 이는 구어체 출처에서 번역하거나 구어체 언어로 번역할 때 오류를 발생시킨다. 일상적인 구어체에서의 번역의 한계는 모바일 기기에서 기계 번역을 사용하는 데 문제를 야기한다.[1]기계 번역을 실현할 때에는 자연어를 컴퓨터로 다루는 데 기인하는 여러 가지 문제에 대처할 필요가 있다. 다음은 일영 번역에서 두드러지게 나타나는 예시이다.[2]
: I ate rice.
위 문장의 경우 "rice" → "ご飯"과 같은 일대일 직역 규칙을 가지고, 통사론에 기반한 어순 변환 처리 등을 통해 "나는 밥을 먹었다"라는 번역문을 출력할 수 있다. 하지만 다음과 같은 문장은 대응하기 어렵다.[2]
: We will have rice harvest tomorrow.
많은 언어 간의 "원어→번역어" 관계와 마찬가지로, 영어의 "rice"에 대응하는 일본어도 여러 개 있으며, 문맥에 따라 "稲"("이네", 벼), "(お)米"("(오)메", 쌀), "ご飯"("고항", 밥) 등으로 번역을 구분할 필요가 있다.[2]
4. 3. 개체명 인식 및 번역
정보 추출에서 개체명은 좁은 의미로 조지 워싱턴, 시카고, 마이크로소프트와 같이 고유 명사를 가지는 실제 세계의 구체적 또는 추상적 개체(사람, 조직, 회사, 장소 등)를 가리킨다. 또한 2011년 7월 1일, 500USD와 같이 시간, 공간, 수량을 나타내는 표현도 포함한다."Smith는 Fabrionix의 사장이다"라는 문장에서 ''Smith''와 ''Fabrionix''는 모두 개체명이며, 이름이나 다른 정보를 통해 더 자세히 설명할 수 있다. 반면 "사장"은 개체명이 아니다. Smith는 이전에 Fabrionix에서 부사장과 같은 다른 직책을 맡았을 수도 있기 때문이다. 엄격 지시어라는 용어는 통계적 기계 번역에서 이러한 용법을 분석하는 데 사용된다.
개체명은 텍스트에서 먼저 식별되어야 한다. 그렇지 않으면 일반 명사로 잘못 번역될 수 있으며, 이는 번역의 BLEU 평가에 영향을 미치지는 않지만 텍스트의 가독성을 떨어뜨릴 수 있다.[37] 개체명이 출력 번역에서 생략될 수도 있는데, 이는 텍스트의 가독성과 메시지에 영향을 미친다.
음역에는 원본 언어의 이름에 가장 가깝게 해당하는 대상 언어의 문자를 찾는 것이 포함된다. 그러나 이는 때때로 번역의 품질을 저하시키는 것으로 알려져 있다.[38] "Southern California"의 경우 첫 번째 단어는 직접 번역해야 하고 두 번째 단어는 음역해야 한다. 기계는 종종 두 단어를 하나의 개체로 취급하기 때문에 두 단어 모두를 음역한다. 이러한 단어들은 음역 구성 요소가 있는 기계 번역기조차도 처리하기 어렵다.
"번역하지 않음" 목록을 사용하는 방법은 음역과 번역의 최종 목표가 동일하지만,[39] 개체명의 정확한 식별에 여전히 의존한다.
세 번째 방법은 클래스 기반 모델이다. 개체명은 그 "클래스"를 나타내는 토큰으로 대체된다. "Ted"와 "Erica"는 모두 "사람" 클래스 토큰으로 대체된다. 그런 다음 "Ted"와 "Erica"의 분포를 개별적으로 살펴보는 대신 일반적으로 사람 이름의 통계적 분포와 사용을 분석하여 특정 언어에서 특정 이름의 확률이 할당된 번역 확률에 영향을 미치지 않도록 할 수 있다. 이 영역의 번역 개선에 대한 스탠퍼드의 연구는 영어를 대상 언어로 할 때 "David is going for a walk"와 "Ankit is going for a walk"에 서로 다른 확률이 할당되는 예를 제시한다. 이는 훈련 데이터에서 각 이름의 발생 횟수가 다르기 때문이다. 스탠퍼드의 동일한 연구(및 개체명 인식 번역 개선을 위한 다른 시도)의 좌절스러운 결과는 개체명 번역 방법을 포함하면 번역의 BLEU 점수가 감소하는 경우가 많다는 것이다.[39]
4. 4. 한국어 특수성
한국어는 다른 언어에 비해 기계 번역에서 특수한 어려움이 존재한다.한국어는 대명사(예: "나", "이것")가 자주 생략되지만, 영어와 같은 언어는 문장에 명확히 포함해야 한다. 따라서 기계 번역 시 생략된 대명사를 적절히 보충해야 한다. 예를 들어,
"동생은 공원에 갔다. 거기서 친구를 만났다."
라는 문장에서 친구를 만난 사람은 "동생"이며, 영어로 번역 시 "He"라는 대명사를 추가해야 한다.
"My brother went to the park. He met his friend there."
하지만 기계 번역은 문장 단위로 번역하는 경우가 많아, 두 번째 문장만으로는 누가 친구를 만났는지 알 수 없다. 앞뒤 문장을 통해 대명사를 추측해야 하며, 복잡한 문장에서는 어떤 대명사를 넣어야 할지 판단하기 어려울 수 있다.
또한, 영어의 "rice"는 문맥에 따라 "벼", "쌀", "밥" 등 여러 가지로 번역될 수 있다. "We will have rice harvest tomorrow." 와 같은 문장을 "우리는 내일 벼 수확을 할 것이다." 와 같이 직역을 하면 어색한 문장이 된다. 이처럼 구문론뿐만 아니라 상식과 의미론을 함께 고려해야 하는 경우가 많다.
예를 들어, "Time flies like an arrow."라는 영어 문장은 의미 분석과 상식적 판단 없이는 여러 가지 번역이 가능하다. "시간은 화살처럼 빨리 지나간다" 외에도 "시간 파리는 화살을 좋아한다", "파리들을 계시하라! 화살처럼(빨리)!"과 같은 번역 결과가 나올 수 있다.
사람은 의미론, 상식, 과거의 언어적 경험을 통해 하나의 번역문을 선택하지만, 기계 번역 시스템은 현실 세계의 상식과 유통되는 문장을 비교하여 잘못된 번역문을 제거해야 한다. "시간은 화살처럼 빨리 지나간다"라는 번역을 선택하려면 "사람은 시간이 빨리 지나간다고 느낄 때가 있다", "화살은 빠르게 날아간다", "일상 대화에서 '시간 파리'와 같은 단어가 등장한 적이 없다" 등의 언어적 경험이 필요하다.
특히 한국어에는 "세월이 화살과 같다"라는 속담이 있으므로, 이러한 지식을 활용하는 것이 좋다.
5. 활용 분야
기계 번역은 아직 완벽하게 자동화된 고품질 번역 시스템은 없지만, 특정 분야로 제한하면 품질이 크게 향상된다.[40][41][42][43] 따라서 번역 속도를 높이거나 임시 번역을 생성하는 데 활용될 수 있다.
기계 번역은 크게 '자동 번역'과 '번역 지원'이라는 두 가지 분야에서 사용된다.[93] 자동 번역은 사람의 개입을 최소화하여 기계가 문장 전체를 번역하는 방식으로, 번역 대상 언어를 이해하지 못하는 사람에게 유용하다. 반면 번역 지원은 전문 번역가가 번역 소프트웨어를 사용하여 보다 효율적이고 정확하게 작업할 수 있도록 돕는 방식이다.
5. 1. 일반 사용자
1998년에는 29.95USD라는 저렴한 가격으로 PC에서 사용할 수 있는 영어와 주요 유럽 언어 간의 단방향 번역 프로그램을 구입할 수 있었다.[14]웹 기반 기계 번역은 시스트란(SYSTRAN)이 소규모 텍스트의 무료 번역 서비스를 제공(1996년)하고 이를 알타비스타 바벨피시(AltaVista Babelfish)를 통해 제공하면서 시작되었으며,[14] 1997년에는 하루에 50만 건의 요청을 처리했다.[17] 두 번째 무료 웹 번역 서비스는 러너우트 앤 하우스피(Lernout & Hauspie)의 글로벌링크(GlobaLink)였다.[14] 1998년 ''애틀랜틱 매거진(Atlantic Magazine)''은 시스트란의 바벨피시와 글로벌링크의 컴프렌드(Comprende)가 "Don't bank on it"을 "능숙하게" 처리했다고 보도했다.[18]
프란츠 요제프 오흐(Franz Josef Och)(구글 번역 개발팀의 미래 책임자)는 2003년 DARPA의 고속 기계 번역 대회에서 우승했다.[19] 이 기간 동안의 다른 혁신으로는 오픈소스 통계 기계 번역 엔진인 모세스(MOSES)(2007년), 일본의 휴대폰용 문자/SMS 번역 서비스(2008년), 영어, 일본어, 중국어를 위한 음성-음성 번역 기능이 내장된 휴대폰(2009년) 등이 있다. 2012년 구글은 구글 번역이 하루에 약 100만 권의 책에 해당하는 분량의 텍스트를 번역한다고 발표했다.
대부분의 휴대 기기, 즉 휴대전화, PDA 등을 위한 기계 번역 애플리케이션도 출시되었다. 휴대성 때문에 이러한 기기는 모바일 번역 도구로 지정되어 서로 다른 언어를 사용하는 파트너 간의 모바일 비즈니스 네트워킹을 가능하게 하거나, 인간 번역가의 중개 없이 외국어 학습과 외국 여행을 용이하게 한다.
예를 들어, 구글 번역 앱을 이용하면 외국인이 스마트폰 카메라를 사용하여 주변의 텍스트를 증강 현실을 통해 빠르게 번역하여 번역된 텍스트를 원래 텍스트 위에 겹쳐서 볼 수 있다.[44] 또한 음성 인식 기능을 통해 음성을 인식하고 번역할 수도 있다.[45]
기계 번역은 위키백과 문서 번역에도 사용되어 왔으며, 특히 기계 번역 기능이 향상됨에 따라 향후 문서 생성, 업데이트, 확장 및 전반적인 개선에 더 큰 역할을 할 수 있다. 편집자가 여러 선택된 언어 간에 문서를 더 쉽게 번역할 수 있도록 하는 "콘텐츠 번역 도구"가 있다.[47][48][49]
최근 웹에서 소셜 네트워킹이 두드러지게 성장하면서 기계 번역 소프트웨어의 또 다른 활용 분야가 생겨났다. 페이스북과 같은 유틸리티나 스카이프, 구글 톡, MSN 메신저 등의 인스턴트 메신저 클라이언트에서 서로 다른 언어를 사용하는 사용자들이 소통할 수 있도록 지원하는 것이다.
리니지W는 기계 번역 기능을 통해 여러 국가의 플레이어들이 소통할 수 있게 해주어 일본에서 인기를 얻었다.[54]
5. 2. 전문 번역
기계 번역은 주로 '자동 번역(기계 번역)'과 '번역 지원(컴퓨터 지원 번역)'이라는 두 가지 다른 분야에서 사용되며, 이 둘은 구분된다.[93] 자동 번역은 인간의 개입을 최소화하여 입력 문장 전체를 기계가 번역하도록 하는 것으로, '번역 원어를 이해할 수 없는 사람'을 위한 기술이다. 반면, 번역 지원은 전문 번역가가 번역 작업을 효율적이고 고품질로 수행할 수 있도록 번역 소프트웨어를 활용하는 것이다. 전자 사전을 컴퓨터에 설치하여 사전 검색을 컴퓨터가 수행하도록 하면서 사람이 번역하는 것은 컴퓨터 지원 번역이라고 불린다.5. 3. 공공 및 기업
1970년대 후반, 제록스는 미국 정부 계약으로 시스트란(SYSTRAN)을 사용해 기술 설명서를 번역했다.[14] 1980년대 후반부터 컴퓨팅 성능 향상과 가격 저하로 통계 기계 번역 모델에 대한 관심이 증가했다.[15] 시스트란의 첫 구현 시스템은 1988년 프랑스 우정청(La Poste (France))의 미니텔(Minitel) 온라인 서비스에 의해 구현되었다.[16] 트라도스(Trados)(1984년 설립) 등 다양한 컴퓨터 기반 번역 회사가 설립되었는데, 트라도스는 번역 메모리 기술(1989년)을 개발 및 판매한 최초의 회사였지만, 이는 기계 번역과는 다르다. 러시아어/영어/독일어-우크라이나어를 위한 최초의 상용 기계 번역 시스템은 하르키우 국립대학교(1991년)에서 개발되었다.1998년에는 29.95USD에 PC에서 사용 가능한 영어와 주요 유럽 언어 간 단방향 번역 프로그램을 구입할 수 있었다.[14]
웹 기반 기계 번역은 시스트란이 소규모 텍스트 무료 번역 서비스를 제공(1996년)하고 알타비스타 바벨피시(AltaVista Babelfish)를 통해 제공하면서 시작되었으며(1997년),[14] 하루 50만 건의 요청을 처리했다.[17] 두 번째 무료 웹 번역 서비스는 러너우트 앤 하우스피(Lernout & Hauspie)의 글로벌링크(GlobaLink)였다.[14] 1998년 ''애틀랜틱 매거진(Atlantic Magazine)''은 시스트란의 바벨피시와 글로벌링크의 컴프렌드(Comprende)가 "Don't bank on it"을 "능숙하게" 처리했다고 보도했다.[18]
프란츠 요제프 오흐(Franz Josef Och)(구글 번역 개발팀의 미래 책임자)는 2003년 DARPA의 고속 기계 번역 대회에서 우승했다.[19] 이 기간 동안의 다른 혁신으로는 오픈소스 통계 기계 번역 엔진인 모세스(MOSES)(2007년), 일본의 휴대폰용 문자/SMS 번역 서비스(2008년), 영어, 일본어, 중국어를 위한 음성-음성 번역 기능이 내장된 휴대폰(2009년) 등이 있다. 2012년 구글은 구글 번역이 하루에 약 100만 권의 책에 해당하는 분량의 텍스트를 번역한다고 발표했다.
완벽한 자동 고품질 기계 번역 시스템은 아직 없지만, 많은 자동 시스템이 상당히 괜찮은 결과물을 생성한다.[40][41][42] 기계 번역의 품질은 특정 분야로 제한하고 통제할 경우 크게 향상된다.[43]
기계 번역 프로그램은 고유한 한계에도 불구하고 전 세계적으로 사용되고 있다. 아마도 가장 큰 기관 사용자는 유럽 연합 집행위원회일 것이다. 2012년, 유럽 연합 집행위원회는 기존의 규칙 기반 기계 번역을 보다 새로운 통계 기반 기계 번역(MT@EC)으로 대체하기 위해 ISA 프로그램을 통해 3072000EUR를 지원했다.[46]
기계 번역은 위키백과 문서 번역에도 사용되어 왔으며, 특히 기계 번역 기능이 향상됨에 따라 향후 문서 생성, 업데이트, 확장 및 전반적인 개선에 더 큰 역할을 할 수 있다. 편집자가 여러 선택된 언어 간에 문서를 더 쉽게 번역할 수 있도록 하는 "콘텐츠 번역 도구"가 있다.[47][48][49] 영어 위키백과에는 650만 개가 넘는 문서가 있는 반면, 독일어 위키백과와 스웨덴어 위키백과에는 각각 250만 개가 넘는 문서만 있다.[51]
기계 번역은 주로 「자동 번역(기계 번역)」과 「번역 지원(컴퓨터 지원 번역)」이라는 다른 응용 분야에서 사용되며, 양자는 구분된다.[93] 자동 번역에서는 인간의 개입이 최소한이며, 입력 문장 전체를 기계에 번역시키려고 한다. 번역 지원은 전문 번역자가 번역 작업을 효율적이고 고품질로 수행하기 위해 번역 소프트웨어를 활용하는 것이다.
5. 4. 의료 및 법률 분야
1966년 미국 정부가 구성한 자동언어처리 자문위원회(Automated Language Processing Advisory Committee)에서 기계 번역은 인간 번역가에 비해 가치 없는 경쟁자로 낙인찍혔지만, 이후 온라인 협업과 의료 분야에서의 응용이 연구될 정도로 발전했다.[55] 인간 번역가가 없는 의료 환경에서 기계 번역 기술을 적용하는 것 또한 연구 주제이지만, 의료 진단에서 정확한 번역의 중요성 때문에 어려움이 따른다.[56]연구자들은 의료 분야에서 기계 번역을 사용할 때 발생할 수 있는 오역의 위험을 경고한다.[57][58] 기계 번역은 의사가 일상적인 활동에서 환자와 소통하는 것을 더 쉽게 만들 수 있지만, 다른 대안이 없을 때만 사용하고 번역된 의학 문서는 정확성을 위해 인간 번역가가 검토해야 한다고 권장한다.[59][60]
법률 용어는 정확성이 요구되고 일반적인 단어 사용과 다른 방식으로 사용되기 때문에 기계 번역 도구에 상당한 어려움을 준다.[61] 기계 번역의 오역 위험 때문에 연구자들은 기계 번역의 정확성을 위해 인간 번역가가 검토해야 한다고 권장하며, 일부 법원에서는 재판 절차에서 기계 번역 사용을 금지한다.[62]
법률 분야에서 기계 번역의 사용은 번역 오류와 의뢰인 비밀 유지에 대한 우려를 제기한다. 구글 번역과 같은 무료 번역 도구를 사용하는 변호사는 번역 도구 제공업체에 개인 정보를 노출함으로써 실수로 의뢰인 비밀 유지 의무를 위반할 수 있다.[61] 또한, 기계 번역으로 얻은 경찰 수색 동의가 무효라는 주장이 제기되었으며, 이러한 주장의 유효성 여부에 대해 법원마다 판결이 다르다.[57]
5. 5. 감시 및 군사
9.11 테러 이후, 미국을 비롯한 서방 국가들은 아랍어 기계 번역 프로그램 개발에 큰 관심을 기울였으며, 파슈토어와 다리어 번역에도 주력했다.[52] 이들 언어 번역에서는 군인과 민간인 간의 신속한 의사소통을 위해 휴대전화 앱을 이용한 주요 구문 번역에 중점을 두었다. 미 국방부 산하 방위고등연구계획국(DARPA) 정보처리기술국은 TIDES (DARPA TIDES program)와 바빌론 번역기(Babylon translator)와 같은 프로그램을 지원했다. 미 공군은 언어 번역 기술 개발에 100만달러의 계약을 체결했다.[53]5. 6. 고대 언어 번역
1970년대 후반, 제록스는 미국 정부 계약으로 시스트란(SYSTRAN)을 사용하여 기술 설명서를 번역했다.[14] 1980년대 후반부터 컴퓨팅 성능 향상과 가격 저렴화로 통계 기계 번역 모델에 대한 관심이 높아졌다. 컴퓨터 등장 이후 기계 번역(MT)은 더욱 대중화되었다.[15]최근 몇 년간 합성곱 신경망 발전과 저자원 기계 번역(훈련에 사용 가능한 데이터와 예시가 매우 제한적인 경우) 기술 발전으로 아카드어와 그 방언인 바빌로니아어, 아시리아어 같은 고대 언어의 기계 번역이 가능해졌다.[63]
6. 평가
기계 번역 시스템의 평가에는 번역의 용도, 기계 번역 소프트웨어의 특성, 번역 과정의 특성 등 다양한 요소가 영향을 미친다. 서로 다른 프로그램은 서로 다른 목적에 효과적일 수 있다. 예를 들어, 통계 기계 번역(SMT)은 일반적으로 예시 기반 기계 번역(EBMT)보다 성능이 뛰어나지만, 영어에서 프랑스어로 번역할 때는 EBMT가 더 나은 성능을 보이기도 한다.[64] 기술 문서는 형식적인 언어 덕분에 SMT를 통해 더 쉽게 번역될 수 있다.
특정 응용 프로그램(예: 제어 언어로 작성된 제품 설명)에서는 사전 기반 기계 번역 시스템이 사람의 개입 없이도 만족스러운 번역을 생성하기도 한다.[65]
기계 번역 시스템의 출력 품질을 평가하는 방법은 여러 가지가 있는데, 대표적으로 자동화된 평가 방법에는 BLEU, NIST, METEOR, LEPOR 등이 있다.[68]
편집되지 않은 기계 번역에만 의존하는 것은 인간 언어에서의 의사소통이 맥락에 포함되어 있다는 사실을 간과하는 것이다. 원본 텍스트의 맥락을 이해하는 데는 사람이 필요하다. 사람이 생성한 번역조차도 오류가 발생하기 쉬우므로, 기계 생성 번역이 유용하고 출판 가능한 품질을 가지려면 사람이 검토하고 편집해야 한다.[69] 클로드 피롱은 기계 번역이 번역가의 작업 중 쉬운 부분을 자동화하고, 어렵고 시간이 많이 걸리는 부분은 대상 언어의 문법적 및 어휘적 요구 사항을 해결하기 위한 광범위한 연구를 포함한다고 언급했다. 이러한 연구는 기계 번역 소프트웨어에 대한 입력을 제공하여 출력이 무의미하지 않도록 하기 위한 사전 편집의 필수적인 전제 조건이다.[70]
모호성 문제 외에도 기계 번역 프로그램에 대한 교육 데이터의 수준이 다양하여 정확도가 저하될 수 있다. 예시 기반 및 통계 기계 번역은 광범위한 실제 예문을 사용하며, 너무 많거나 너무 적은 문장을 분석하면 정확도가 떨어진다. 연구에 따르면 203,529개의 문장 쌍으로 훈련했을 때 정확도가 감소했으며,[64] 최적의 교육 데이터 수준은 100,000개 이상의 문장일 수 있다. 훈련 데이터가 증가하면 가능한 문장의 수가 증가하여 정확한 번역 일치를 찾기 어려워지기 때문이다.
기계 번역의 결함은 오락적 가치로 인해 주목받기도 한다. 2017년 4월에 유튜브에 업로드된 두 개의 비디오에서는 일본어 히라가나 문자 えぐ (''e'' 및 ''gu'')를 구글 번역에 반복적으로 붙여넣었을 때 "DECEARING EGG", "Deep-sea squeeze trees"와 같은 무의미한 구문으로 번역되는 현상을 보여주었다.[71][72] 이 비디오의 전체 버전은 2022년 3월 기준으로 690만 회 이상의 조회수를 기록했다.[73]
6. 1. 수동 평가
기계 번역 시스템의 출력 품질을 평가하는 가장 오래된 방법은 사람 심사관이 번역 품질을 평가하는 것이다.[66] 사람에 의한 평가는 시간이 많이 걸리지만, 규칙 기반 시스템과 통계 시스템과 같이 서로 다른 시스템을 비교하는 가장 신뢰할 수 있는 방법이다.[67]수동 평가는 사람이 직접 번역 결과물을 평가하는 방식으로, 번역의 품질을 평가하기 위해 인간 평가자를 활용한다. 평가자는 번역된 문장을 읽고 다음과 같은 기준에 따라 점수를 매긴다.
| 점수 | 설명 |
|---|---|
| 5 | 어색함이 없고, 의미도 정확함. |
| 4 | 약간 어색하지만, 의미는 대체로 이해 가능함. |
| 3 | 어색하고, 의미를 이해하기 어려움. |
| 2 | 어색하며, 곳곳에 오역이 포함됨. |
| 1 | 번역이 완전히 망가져 있음. |
각 문장에 대해 위와 같은 지침에 따라 점수를 매기고, 각 평가의 비율(예: 어떤 점수의 문장이 몇 퍼센트 포함되어 있는지)을 계산하여 번역 시스템의 평가 결과로 삼는다. 여러 기준에 따라 평가하거나, 평가자가 자유롭게 의견을 남길 수 있도록 하여 단순한 점수 매기기를 넘어 시스템 개선으로 이어질 수 있다.
6. 2. 자동 평가
기계 번역 시스템의 출력 품질을 평가하는 방법에는 인간 평가와 자동 평가가 있다. 인간 평가는 번역 품질을 평가하기 위해 인간 심사관을 사용하는 것으로,[66] 시간이 많이 걸리지만 규칙 기반 시스템과 통계 시스템 등 서로 다른 시스템을 비교하는 가장 신뢰할 수 있는 방법이다.[67]자동 평가는 기계 번역 결과를 기계적으로 평가하는 방법이다. 평가를 수행하려면 먼저 원문과 참조 번역(번역의 정답 문장)을 수천 쌍 정도 준비하고, 번역 시스템을 사용하여 원문을 번역한다. 그 후, 번역 결과와 참조 번역의 유사도를 각 문장에 대해 계산하고, 마지막으로 평균을 내어 번역 시스템의 평가로 삼는다.
자동 평가 지표로는 다음과 같은 것들이 있으며, 각 지표마다 특징이 있으므로 하나의 지표만을 신뢰하기보다는 여러 지표를 병용하는 것이 바람직하다.
- BLEU
- General Text Matcher(GTM)
- IMPACT
- METEOR
- 위치 독립 단어 오류율(Position-independent word Error Rate, PER)
- RIBES
- Translation Error Rate(TER)
- Word Error Rate(WER)
7. 저작권
저작권 보호를 받는 것은 창작물 중에서도 독창성이 있는 것에 한정되므로, 기계 번역 결과는 창작성이 개입되지 않기 때문에 저작권 보호 대상이 아니라고 주장하는 학자들도 있다.[75] 문제가 되는 저작권은 2차 저작물에 대한 것이며, 원어로 된 독창성 있는 원저작물의 저작자는 작품이 번역되더라도 자신의 권리를 잃지 않는다. 번역본을 출판하려면 번역가는 반드시 허가를 받아야 한다.
저작권의 보호를 받는 것은 독창적인 저작물뿐이며, 기계 번역에는 창작성이 없으므로 기계 번역 결과는 저작권 보호를 받을 권리가 없다고 일반적으로 생각된다.[95] 또한 그렇게 주장하는 학자도 있다.[96] 문제가 되는 저작권은 2차 저작물(영: derivative work)에 관한 것이다. 원어로 작성된 원저작물(영: original work)의 저자[97]는 자신의 작품이 번역될 때 권리를 잃지 않으며, 번역자는 번역물을 출판하려면 허가를 받아야 한다.
8. 종류
- 구글 번역
- 시스트란
- 바벨피시
- 빙 번역기
- 네이버 파파고
- 마이크로소프트 번역기
참조
[1]
웹사이트
Google Translate Gets a Deep-Learning Upgrade
https://spectrum.iee[...]
2016-10-03
[2]
웹사이트
Google Translate vs. ChatGPT: Which One Is the Best Language Translator?
https://uk.pcmag.com[...]
2024-02-23
[3]
웹사이트
The Cryptological Origins of Machine Translation: From al-Kindi to Weaver
https://web.archive.[...]
2018-01-01
[4]
서적
Universal Language Schemes in England and France, 1600-1800
University of Toronto Press
1975
[5]
서적
Computers and Automation 1953-05: Vol 2 Iss 4
https://archive.org/[...]
Berkeley Enterprises
1953-05-01
[6]
서적
Early Years in Machine Translation
https://web.archive.[...]
[7]
웹사이트
Warren Weaver, American mathematician
https://www.britanni[...]
2020-07-13
[8]
서적
パーソナルコンピュータによる機械翻訳プログラムの制作
(株)ラッセル社
1986-08-13
[9]
웹사이트
機械翻訳専用機「やまと」-コンピュータ博物館
https://web.archive.[...]
[10]
학술지
Speaking in Tongues: Science's centuries-long hunt for a common language
https://www.scienceh[...]
2016
[11]
서적
Scientific Babel: How Science Was Done Before and After Global English
University of Chicago Press
2015
[12]
뉴스
David G. Hays, 66, a Developer Of Language Study by Computer
https://www.nytimes.[...]
1995-07-28
[13]
서적
パーソナルコンピュータによる機械翻訳プログラムの制作
(株)ラッセル社
1986-08-13
[14]
잡지
Lost in Translation
1998-12-01
[15]
서적
Conceptual Information Processing
Elsevier
2014
[16]
서적
Machine Translation and the Information Soup: Third Conference of the Association for Machine Translation in the Americas, AMTA'98, Langhorne, PA, USA, October 28–31, 1998 Proceedings
Springer
2003-06-29
[17]
웹사이트
Babel Fish: What Happened To The Original Translation Application?: We Investigate
https://digital.com/[...]
2019-11-18
[18]
기타
[19]
서적
Routledge Encyclopedia of Translation Technology
Routledge
2015
[20]
웹사이트
Google Translator: The Universal Language
https://web.archive.[...]
Blog.outer-court.com
2007-01-25
[21]
학회
Multi-Source Translation Methods
https://dowobeha.git[...]
2008
[22]
학회
Machine Translation by Triangulation: Making Effective Use of Multi-Parallel Corpora
https://web.archive.[...]
2007
[23]
학술지
Improving Statistical Machine Translation for a Resource-Poor Language Using Related Resource-Rich Languages
https://jair.org/ind[...]
2012
[24]
논문
Attaining the unattainable? reassessing claims of human parity in neural machine translation
2018
[25]
논문
Translationese in Machine Translation Evaluation
2019
[26]
학술지
Poor English skills? New AIs help researchers to write better
2022-08-29
[27]
웹사이트
DeepL: An Exceptionally Magnificent Language Translator
https://towardsdatas[...]
2022-02-18
[28]
뉴스
DeepL outperforms Google Translate – DW – 12/05/2018
https://www.dw.com/e[...]
[29]
논문
How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation
2023-02-18
[30]
뉴스
Study assesses the quality of AI literary translations by comparing them with human translations
https://techxplore.c[...]
[31]
논문
Exploring Document-Level Literary Machine Translation with Parallel Paragraphs from World Literature
2022-10-25
[32]
학회
Findings of the 2023 Conference on Machine Translation (WMT23): LLMs Are Here but Not Quite There Yet
https://aclanthology[...]
Association for Computational Linguistics
2023
[33]
웹사이트
Milestones in machine translation – No.6: Bar-Hillel and the nonfeasibility of FAHQT
https://web.archive.[...]
2007-03-12
[34]
웹사이트
Automatic Translation of Languages
https://web.archive.[...]
1960
[35]
서적
Hybrid approaches to machine translation
2016-07-21
[36]
서적
Le défi des langues (The Language Challenge)
L'Harmattan
1994
[37]
학회논문
Improving Machine Translation Quality with Automatic Named Entity Recognition
http://www.cl.cam.ac[...]
2013-11-04
[38]
논문
Name Translation in Statistical Machine Translation Learning When to Transliterate
http://www.aclweb.or[...]
Association for Computational Linguistics
2008-01-01
[39]
논문
Using Named Entity Recognition to improve Machine Translation
http://nlp.stanford.[...]
[40]
서적
The Possibility of Language
http://www.benjamins[...]
Benjamins.com
1995
[41]
웹사이트
A Simple Model Outlining Translation Technology
http://tandibusiness[...]
2006-02-14
[42]
웹사이트
Appendix III of 'The present status of automatic translation of languages', Advances in Computers, vol.1 (1960), p.158-163. Reprinted in Y.Bar-Hillel: Language and information (Reading, Mass.: Addison-Wesley, 1964), p.174-179.
https://web.archive.[...]
[43]
웹사이트
Human quality machine translation solution by Ta with you
http://tauyou.com/bl[...]
Tauyou.com
2009-04-15
[44]
뉴스
Google Translate Adds 20 Languages To Augmented Reality App
https://www.popsci.c[...]
2015-07-30
[45]
뉴스
Google Translate app update said to make speech-to-text even easier
https://www.cnet.com[...]
[46]
웹사이트
Machine Translation Service
http://ec.europa.eu/[...]
2011-08-05
[47]
뉴스
Wikipedia has a Google Translate problem
https://www.theverge[...]
2019-05-08
[48]
뉴스
Wikipedia taps Google to help editors translate articles
https://venturebeat.[...]
2019-01-09
[49]
웹사이트
Content translation tool helps create over half a million Wikipedia articles
https://wikimediafou[...]
2019-09-23
[50]
웹사이트
Wikipedia Has a Language Problem. Here's How To Fix It.
https://undark.org/2[...]
2021-08-12
[51]
웹사이트
List of Wikipedias - Meta
https://meta.wikimed[...]
[52]
웹사이트
Machine Translation for the Military
http://www.theworld.[...]
2011-04-26
[53]
웹사이트
GCN – Air force wants to build a universal translator
http://gcn.com/artic[...]
Gcn.com
2003-09-09
[54]
웹사이트
Korean Games Growing in Popularity in Tough Japanese Game Market
http://www.businessk[...]
2023-06-26
[55]
보고서
Language and Machines: Computers in Translation and Linguistics
http://www.nap.edu/h[...]
National Research Council, National Academy of Sciences
1966-01-01
[56]
학술지
Using machine translation in clinical practice
http://www.cfp.ca/co[...]
2013-04-01
[57]
학술지
Understanding the societal impacts of machine translation: a critical review of the literature on medical and legal use cases
2021-08-18
[58]
학술지
Assessing the Use of Google Translate for Spanish and Chinese Translations of Emergency Department Discharge Instructions
2019-04-01
[59]
학술지
Plurilingualism, multimodality and machine translation in medical consultations: A case study
http://www.jbe-platf[...]
2022-07-05
[60]
학술지
The Use of Machine Translation for Outreach and Health Communication in Epidemiology and Public Health: Scoping Review
2023-11-20
[61]
웹사이트
Man v. Machine: Social and Legal Implications of Machine Translation
https://legaljournal[...]
2023-01-02
[62]
학술지
New Mexico's Success with Non-English Speaking Jurors
https://heinonline.o[...]
2008-01-01
[63]
학술지
Translating Akkadian to English with neural machine translation
https://academic.oup[...]
2023-05-02
[64]
학술지
Comparing Example-Based and Statistical Machine Translation
2005-09-20
[65]
논문
Fully Automatic High Quality Machine Translation of Restricted Text: A Case Study
http://www.mt-archiv[...]
Aslib
2006-11-16
[66]
웹사이트
Comparison of MT systems by human evaluation, May 2008
https://web.archive.[...]
Morphologic.hu
[67]
논문
Machine translation as a tool in second language learning
http://citeseerx.ist[...]
1995-01-01
[68]
논문
LEPOR: A Robust Evaluation Metric for Machine Translation with Augmented Factors
http://repository.um[...]
2012-01-01
[69]
기타
Scientific translation is the aim of an age that would reduce all activities to techniques. It is impossible however to imagine a literary-translation machine less complex than the human brain itself, with all its knowledge, reading, and discrimination.
[70]
웹사이트
annually performed NIST tests since 2001
https://www.nist.gov[...]
[71]
웹사이트
4 times Google Translate totally dropped the ball
https://www.business[...]
[72]
웹사이트
回数を重ねるほど狂っていく Google翻訳で「えぐ」を英訳すると奇妙な世界に迷い込むと話題に
https://nlab.itmedia[...]
[73]
웹사이트
えぐ
https://www.youtube.[...]
2017-04-12
[74]
논문
A Machine Translation System from English to American Sign Language
http://repository.up[...]
2000
[75]
웹사이트
Machine Translation: No Copyright On The Result?
http://www.seo-trans[...]
SEO Translator, citing Zimbabwe Independent
2012-11-24
[76]
웹사이트
翻訳実験用計算機KT-1 論理パッケージ,磁気ドラム-コンピュータ博物館
http://museum.ipsj.o[...]
2024-04-15
[77]
웹사이트
機械翻訳専用機「やまと」-コンピュータ博物館
http://museum.ipsj.o[...]
2024-04-15
[78]
간행물
Machine Translation in Foreign Language Learning: Language Learners's and Tutor's Perceptions of Its Advantages and Disadvantages
2009-05
[79]
논문
機械翻訳の新しいパラダイム:ニューラル機械翻訳の原理
https://www.jstage.j[...]
2017
[80]
웹사이트
「急速に進化した機械翻訳」に、それでもできない3つのこと(西田 宗千佳)
http://gendai.media/[...]
2024-04-15
[81]
뉴스
日本経済新聞
2021-01-11
[82]
웹사이트
NVIDIA ジェンスン・フアンCEO、対話型AIサービス「Jarvis」で「じゃんがらラーメン」を探すデモ
https://car.watch.im[...]
株式会社インプレス
2021-04-14
[83]
서적
パソコン翻訳の世界
1997
[84]
웹사이트
エキサイト翻訳がサービス終了へ、22年間の歴史にネット「一つの時代が終わった」
https://news.mynavi.[...]
2022-10-13
[85]
웹사이트
「DeepL」の驚くほど自然な翻訳に迫る。失敗しない使い方 - Impress Watch
https://www.watch.im[...]
[86]
웹사이트
Google翻訳を超えた? 新しい翻訳サービス「DeepL」がその精度の高さで話題に【やじうまWatch】
https://internet.wat[...]
株式会社インプレス
2020-03-23
[87]
웹사이트
無料で“Google 翻訳”より高精度! “みらい翻訳”のお試し翻訳が便利/TOEIC960点レベルのビジネスマンと同等の翻訳精度【やじうまの杜】
https://forest.watch[...]
株式会社インプレス
2019-04-25
[88]
웹사이트
https://www.nri.com/[...]
[89]
웹사이트
「急速に進化した機械翻訳」に、それでもできない3つのこと(西田 宗千佳)
http://gendai.media/[...]
2024-04-15
[90]
웹사이트
3-F ニューラル機械翻訳は翻訳プロセスをどう変えていくか-最近の機械翻訳技術と利用に関する動向- | JTFジャーナルWeb版 | 一般社団法人日本翻訳連盟 機関誌
https://journal.jtf.[...]
[91]
논문
Deciphering Foreign Language
2011
[92]
웹사이트
機械翻訳の新時代:大規模言語モデルはライオン達の夢を見るか?[1]
https://blog.sunflar[...]
[93]
웹사이트
著作権審議会第9小委員会(コンピュータ創作物関係)報告書 著作権審議会/文化審議会分科会報告 著作権データベース 公益社団法人著作権情報センター CRIC
https://www.cric.or.[...]
[94]
웹사이트
SDL Machine Translation
https://www.sdl.com/[...]
[95]
웹사이트
著作権審議会第9小委員会(コンピュータ創作物関係)報告書 著作権審議会/文化審議会分科会報告 著作権データベース 公益社団法人著作権情報センター CRIC
https://www.cric.or.[...]
公益社団法人著作権情報センター
[96]
웹사이트
Machine Translation: No Copyright On The Result?
http://www.seo-trans[...]
SEO Translator, citing Zimbabwe Independent
[97]
기타
[98]
잡지
Lost in Translation
1998-12
[99]
뉴스
[지식충전소] “얼라 했더니 Kid…3년 내 사투리까지 자동번역”
https://news.naver.c[...]
중앙일보
2016-10-19
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com